Political Stances: Association Rule Mining
There are multiple associtations within natural language. Texts we generate are embedded with nuance and word senses and further analysis may provide insight into the nuance of word co-occurance. For example, consider the word “climate” and words which may trail after it. “Change” may be a suitable word to follow “climate”. But what are other possibilities of words that may follow, and in a specific text corpus like news and introduced climate bills at the federal level. Using Association Rule Mining, a systematic analysis may be conducted about what words are most likely to follow in suite from the next.
Table of Contents
- Metrics of Association Rule Mining
- Data Preparation
- Association Rules for Climate, Government, Republican, and Democrat
- Most Meaningful Rules for Support, Lift, and Confidence
- Conclusions
Metrics of Association Rule Mining
Support, Confidence, and Lift are measures that are used to inform how relevant a rule is across the corpus. I will briefly explain them, as they are used to anchor the analysis presented here.
Support is calculated using the frequency of two words co-occuring. For example, if there are 100 words in the corpus, and the word ‘climate’ occurs ten times and it co-occurs with ‘shift’ only once. This means the value of support for the rule climate -> shift would be 0.01.
Confidence is calculated using frequency of one word co-occuring for the amount of times the first word occurs. Using the same example as above, the word ‘climate’ occured ten times, and ‘shift’ occured once when climate was present. This means that the confidence of the rule climate -> is 0.1.
Lift is calculated using the value of support. The numerator is the value of support for a particular rule. The denominator is then how often the first word occurs in the corpus multiplied by that of the frequency the second word occurs in the corpus. This metric is utilized to illustrate the significance of the relationship. If the value is exactly one, this indicates a relationship that is independent of the other.
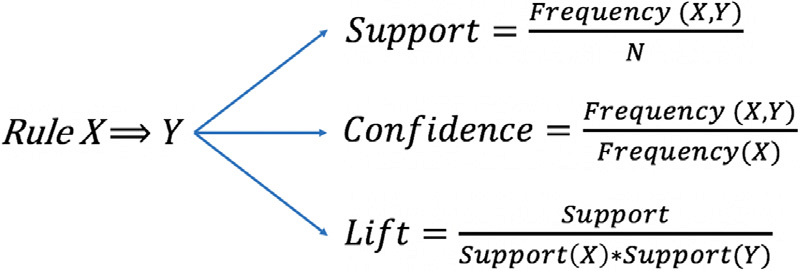
Image Citation: Yaman, Sezin, Fabian Fagerholm, Myriam Munezero, Tomi Männistö, and Tommi Mikkonen. “Patterns of User Involvement in Experiment-Driven Software Development.” Information and Software Technology 120 (April 2020): 106244. https://doi.org/10.1016/j.infsof.2019.106244.
The Apriori Algorithm is what ARM operates on. It specifically uses transcript data, which reads the rows and then generates an understanding of co-occurance within documents. The algorithm is bottom up and begins to count any rules that co-occur in each document.
Data Preparation
Association Rule Mining (ARM) is the task of understanding interactions through transaction data. Transaction data represents a collection of documents where each row is a document. The columns then illustrate the words which compose each row, or transaction. Take the sentence ‘The ocean is blue and the ocean is big’, the row would compose of the words ‘ocean’, ‘blue’, ‘big’. Words like stop words are removed from the data because they are frequent, and likely to co-occur with most of the words because of their syntactical functions. In addition to filtering out the stopwords, pre-processing data for ARM does not rely on frequencies, just the presence of the words. In short, ARM takes transaction data, which is composed of the unique meaningful words in each document. To view how basket data was generated, reference the code provided here, the data is stored at this HuggingFace Repository. A snippet of the transaction data is illustrated below. This continues on with however many documents compose the total corpus. The transactions illustrated in the screenshot are short because they are news headlines, however, further down in the corpus are the climate bills which extend beyond just a few words.

To preform ARM, R was utilized. The full code used to describe the visuals provided below are presented in ARM - CODE or provided at my GitHub. The R file and workspace may also be downlaoaded at the provided link.
Association Rules for Climate, Government, Republican, and Democrat
Association role mining was identified based on words which co-occur. The large amount of data originally presented to the model generated over 11,000 rules. These rules alone were far reaching, and after filtering for lift validity did not provide much shape to the data. To mediate this, words were selected it order to identify what was the most meaningfully co-occurring in certain contexts. To do so the words “climate”, “Democrat”, “Republican”, “Science”, “Tribal”, “Government”. The most confident rules were then selected to be visualized. First, the rules for climate and government are described to illustrate the embedding space. Then, the partisian representations for “Democrat” and “Republican” are both discussed.
The figures illustrated below are generated using lemmatized data. This allows for a merge of multiple word forms with the same word senses to be illustrated visually. If you see words that are incomplete like ‘extren’ this may be representing “externally”, or “external”
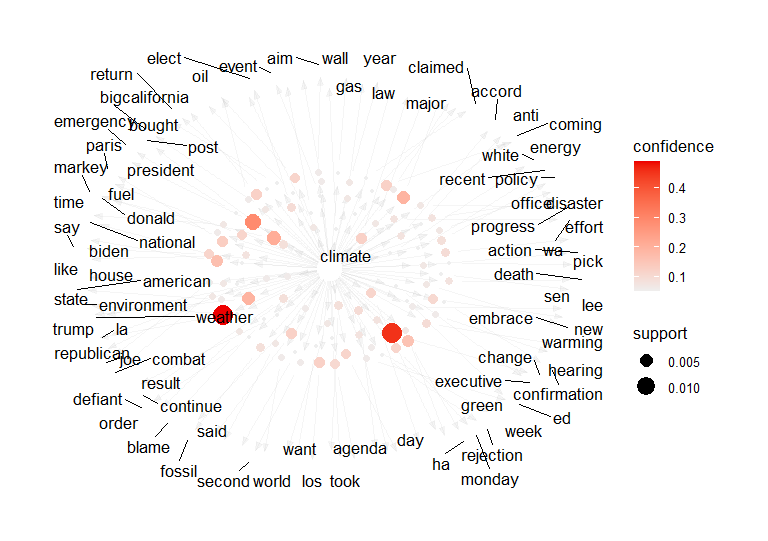
Climate Associations
The highgest supported accosciations when climate is present are the words "weather","change", and "president"

Government Associations
Some associations with multiple co-occurances are "government, contribution, cause", "governmnet, prepare, maintain" and "government, contract, science".

Republican Associations
Republican ARM rules highlight more concerns about immigration and climate change.
GOP Party Platform - Clean Text
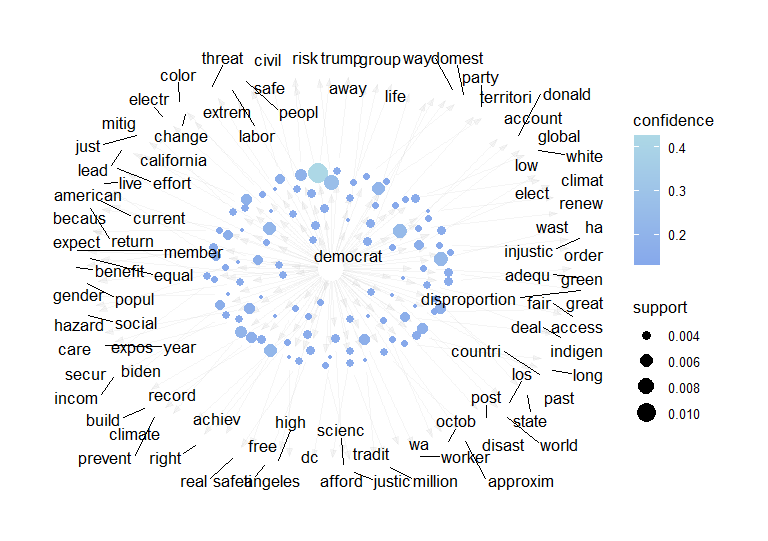
The Democrat ARM rules foucs more on words describing concen, like 'disproportion', 'fair', and 'threat'.
Co-occurrence rules generated from the word “tribal” are illustrative of the specific environmental concerns which originate from Indigenous land. The term ‘tribal’ was selected here in opposition to ‘indigenous’ or ‘First Nation’ because ‘tribal’ is the language utilized by the federal government, thus would be more representative of the climate policies introduced on behalf or facilitated by Indigenous peoples. The words which are illustrative of the specific concerns on territories are “fish”, “basin”, “wildfire”, and “industri-“. Further illustrated are the particular entities which co-occur with tribal: “member”, “indian”, “scientific”, “district”, “private”, “non-profit”, and ”head”. Due to the language constraints illustrated above, it may be expected that the word “tribal” may not be as frequent in media coverage as it is in federal bills. For this reason, the entities described here may be illustrative of the actors most involved in Indigenous concern about policy.
Strong action oriented phrases are also utilized which illustrate the kinds of mitigation measures discussed in Indigenous climate policy. The most prevalent rules are: “restore”, “converse”, “promote”, “create”, “strategy”, “enforce”, “prevent”, “perform, “and “mitigate”. These words are more specific than that illustrated in either “science” or “government.” This may be a result of the language utilized, however, an overwhelming proportion of the data distribution belongs to Republican and Democrat focused climate bills, and strong action words may be more illustrative of the kinds of efforts or bills that each side is proposing for law.
For the term ‘Republican” the most confident rules which mention climate related activities (tangentially) are: “wildfire” and “land”. In comparison to the rules generated from Democrat co-occurrences words “climate”, “los” (also referring to wildfires), “green”, “climat”. It should be noted that while both presidents are illustrated in the climate embedding space, only ‘Republican” is present. The Republican associations are more concerned with fiscal resources, policy shifts and governing entities, or immigration. This may be illustrated through rules like “immigration”, “anti”, or “vote”.
Rules generated from ‘Democrat’ co-occurrence illustrate more emotion that illustrate concern. These rules may be illustrated with “injustice” , “justice”, “safe” or “benefit”. These words, or words with similar word senses were not illustrated in the Republican affiliated rules with the most confidence. This may demonstrate the kinds of language used to construct media and policy about the Democrats are inherently more emotional and concerned with justice. In addition, the co-occurrence with words that may be related to climate change is higher. Words that are used to illustrate this are: “green”, “waste”, “disaster”, “hazard”, and “extreme”. These words also co-occur alongside of marginalized groups such as “gender”, “territories”, “indigenous”, and “color”. The combination of the rules presented show a fundamentally different media and policy space.
The language used to construct narratives about climate change and climate related concerns are politically siloed. Co-occureances most likely in the Republican group are more aligned the words that co-occurred with the word “government”. Neither of the co-occurrence spaces are closely aligned with that of the “scientific” or “tribal” associations.
15 Most Meaningful Rules for Support, Lift, and Confidence
Support
The top 15 rules for support are concerned first with legislative outcomes. Support measures the frequency across the entire dataset, so these numbers in relative to confidence and lift will be lower. However, these will have a higher count because support measures what is most likely to co-occur across the entire dataset. Rules like ‘moment’ and ‘just’ may illustrate news as they often report on the current moment. Rules like ‘coordin’ and ‘reccomend’ illustrate the coordiation and planning required to successfully pass climate bills. This rule or even keyword are not present in the above explored topic specific word clouds. This suggests that the use of ‘moment’, ‘just’, ‘coordin’, and ‘reccomend’ are illustrative of a specific process, and are not affiliated with a specifc partisian affiliation more than the next. The rule ‘tribe’ and ‘indian’, and its inverse, was also included in the highest co-occurance. This suggests that when referencing policy about Indigenous and First Nation People in the United States, they are referred to both as a group and also “Indian”.
| rules | support | confidence | lift | count |
|---|---|---|---|---|
| {fall} => {speaker} | 0.131276023 | 0.942003515 | 6.453356 | 536 |
| {speaker} => {fall} | 0.131276023 | 0.899328859 | 6.453356 | 536 |
| {moment} => {just} | 0.105069802 | 0.977220957 | 7.499987 | 429 |
| {just} => {moment} | 0.105069802 | 0.806390977 | 7.499987 | 429 |
| {rem} => {just} | 0.104579966 | 0.979357798 | 7.516387 | 427 |
| {just} => {rem} | 0.104579966 | 0.802631579 | 7.516387 | 427 |
| {rem} => {max} | 0.10409013 | 0.974770642 | 9.364679 | 425 |
| {rem} => {moment} | 0.10409013 | 0.974770642 | 9.066033 | 425 |
| {moment} => {max} | 0.10409013 | 0.968109339 | 9.300683 | 425 |
| {moment} => {rem} | 0.10409013 | 0.968109339 | 9.066033 | 425 |
| {just} => {max} | 0.10409013 | 0.79887218 | 7.674812 | 425 |
| {coordin} => {recommend} | 0.103600294 | 0.621145374 | 3.638646 | 423 |
| {recommend} => {coordin} | 0.103600294 | 0.606886657 | 3.638646 | 423 |
| {tribe} => {indian} | 0.103110458 | 0.931415929 | 8.376589 | 421 |
| {indian} => {tribe} | 0.103110458 | 0.927312775 | 8.376589 | 421 |
Lift
Lift is not as illustrative about keyword specific rules or that of support. Lift measures the dependence between items, and uses the presence of one to measure the presence of the other. This measure inform how often one word is present when the other is present. For these reasons, the overwhelming majority of rules with the highest lift illustrate the numerical ordering of the federal regulations. These are used to enumerate specific policies in the bills, but are so frequent they mask the presence of the context itself. This suggests a need to either (1) remove the Roman Numerals and loose some hierachical structuring of the text, (2) use another metric to identify the most meaningful rules, like support, (3) use specific words to frame an ARM analysis.
| rules | support | confidence | lift | count |
|---|---|---|---|---|
| {vi,viii} => {ix} | 0.056086211 | 0.765886288 | 12.92196 | 229 |
| {vi,vii,viii} => {ix} | 0.056086211 | 0.765886288 | 12.92196 | 229 |
| {vii,viii} => {ix} | 0.056086211 | 0.763333333 | 12.87888 | 229 |
| {ix,vi,vii} => {viii} | 0.056086211 | 0.974468085 | 12.87622 | 229 |
| {ix,vii} => {viii} | 0.056086211 | 0.970338983 | 12.82166 | 229 |
| {ix,vi} => {viii} | 0.056086211 | 0.970338983 | 12.82166 | 229 |
| {ix} => {viii} | 0.056086211 | 0.946280992 | 12.50377 | 229 |
| {viii} => {ix} | 0.056086211 | 0.741100324 | 12.50377 | 229 |
| {reg} => {fed} | 0.08131276 | 0.994011976 | 11.56282 | 332 |
| {fed} => {reg} | 0.08131276 | 0.945868946 | 11.56282 | 332 |
| {aa,bb} => {cc} | 0.05143277 | 0.601719198 | 11.32175 | 210 |
| {basi,bb} => {aa} | 0.054616703 | 0.991111111 | 11.30365 | 223 |
| {aa,basi} => {bb} | 0.054616703 | 0.986725664 | 11.28516 | 223 |
| {bb,vi} => {aa} | 0.061719324 | 0.988235294 | 11.27085 | 252 |
| {bb,cc} => {aa} | 0.05143277 | 0.985915493 | 11.24439 | 210 |
Confidence
Similarly to lift, confidence preforms similarly. There is an increased variatio in co-occurance, even with the Roman Numerals, which may suggest other considerations about how the bills are structured. For example, in Roman Numeral VII the words ‘recommend’, ‘specif’, ‘known’, and ‘maximum’ were most likely to be present. In Roman Numeral VI ‘serv’, ‘studi’, ‘particip’, and ‘technic’ can be identified. This may provide an insight into how climate bills are structured, and the concerns hierachically nested in the text.
| rules | support | confidence | lift | count |
|---|---|---|---|---|
| {vii,viii} => {vi} | 0.073230468 | 0.996666667 | 6.805 | 299 |
| {recommend,vii} => {vi} | 0.064413422 | 0.996212121 | 6.801896 | 263 |
| {forth} => {set} | 0.061719324 | 0.996047431 | 7.340906 | 252 |
| {specif,vii} => {vi} | 0.060739652 | 0.995983936 | 6.800338 | 248 |
| {known,vii} => {vi} | 0.05975998 | 0.995918367 | 6.799891 | 244 |
| {maximum,vii} => {vi} | 0.058290473 | 0.9958159 | 6.799191 | 238 |
| {ix,vi} => {vii} | 0.057555719 | 0.995762712 | 9.634358 | 235 |
| {ix,vii} => {vi} | 0.057555719 | 0.995762712 | 6.798828 | 235 |
| {evalu,vii} => {vi} | 0.057065883 | 0.995726496 | 6.798581 | 233 |
| {dispos,solid} => {wast} | 0.056576047 | 0.995689655 | 7.627394 | 231 |
| {technic,vii} => {vi} | 0.053637032 | 0.995454545 | 6.796724 | 219 |
| {contentsth,sec} => {tabl} | 0.051922606 | 0.995305164 | 10.15958 | 212 |
| {serv,vii} => {vi} | 0.051677688 | 0.995283019 | 6.795553 | 211 |
| {studi,vii} => {vi} | 0.051677688 | 0.995283019 | 6.795553 | 211 |
| {particip,vii} => {vi} | 0.05143277 | 0.995260664 | 6.7954 | 210 |
Conclusions:
Association Rule Mining illustrates co-occurance between words. The rules with the highest confidence and lift were overwhelmingly about the structure of the documents. The way in which lift and confidence are calculated, enable the top fifteen rules to be the most expected: roman numerals. For this corpus, support, may be more appropriate to understand the most likley associations. A few examples are “fall” to “speaker”, “coordinate” to “reccomend”, and “tribe” to “indian”. These rules suggest that a specific analysis requires a scoping term like ‘Republican’ or ‘Democrat’.
This specifically helps to answer questions about named concerns, like ‘climate’, ‘government’ or partisan affiliations. Republican was most affiliated with concerns about immigration and the physical action of cliamte change. Democrat was most affiliated with words of concern like ‘disproportion’, ‘fair’, or ‘threat’. Neither climate or government have clear overlap with either of the partisan associated rules. Association with the word ‘tribal’ (word choice was rationalized earlier) illustrated more co-occurance with words discussing mitigation like ‘promote’, ‘enforce’, and ‘mitigate’. The language used to construct narratives about climate change are politically siloed.