Political Stances: Neural Networks
Overview
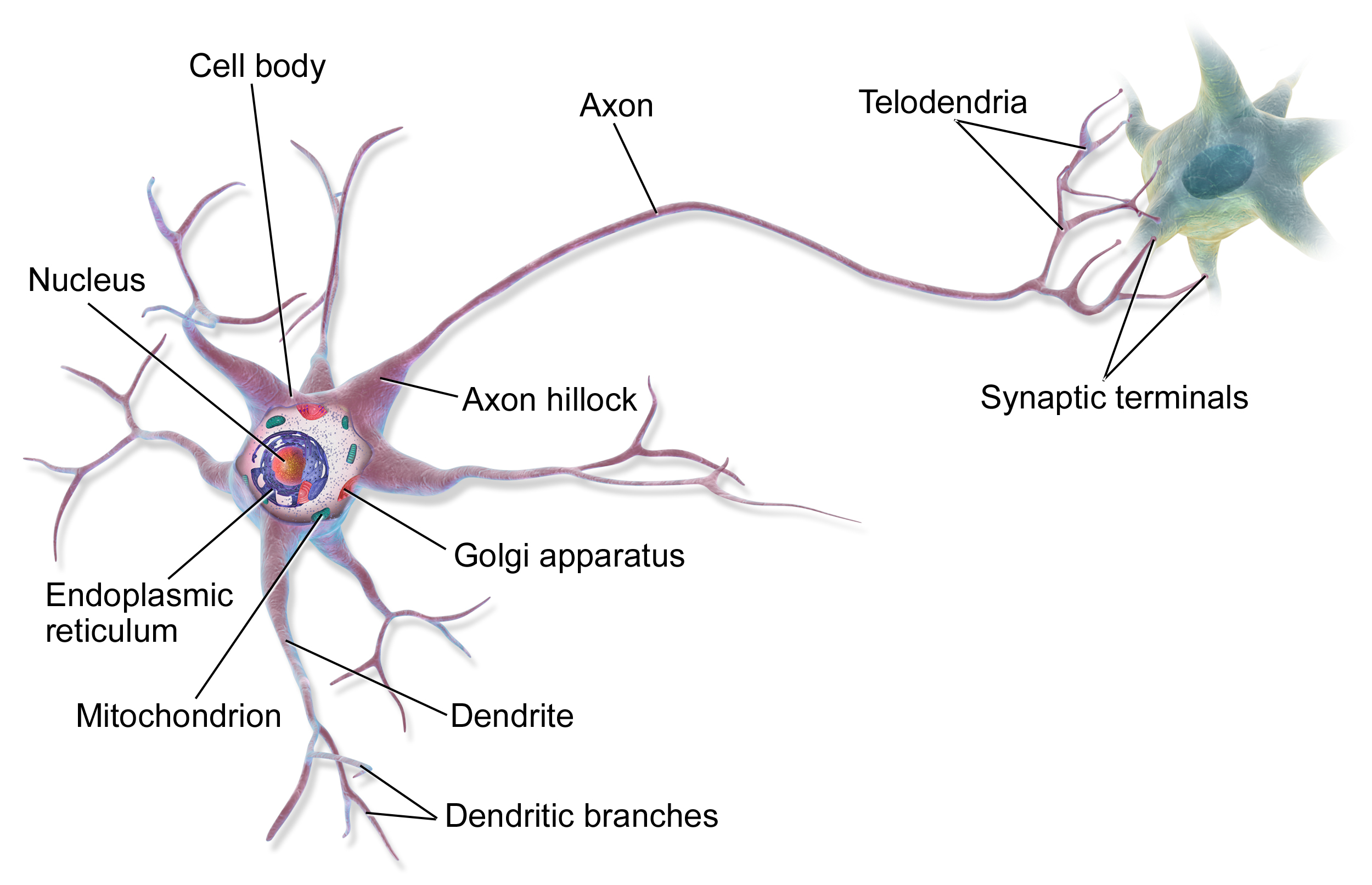
A Neural Network, is inspired (loosely) by the neurological structure of the neurons in our brains. It mirrors the dendritic branches through the vectorized input layer of the text. The branches then pass in to the nucleas, where the input layer is transformed into an output signal, in the case of a neural network this is represented as y, but in the case of the brain it may be represented as an itch, yell, or laugh. The structure of a neural network unit is roughly as follows: the network takes an input layer (a sentence), converts it to numbers so it is computer readable (vectorization), then generates weights (learned through backpropoagation of the neural network), preforms a transformation to interpret the input (sigmoid or some other activation function), and then normalizes the output into something bounded (softmax). This is then repeated multipls times to train multi-layered network, and has formed the later intution for more complicated techniques like transformers.
What is the advantage of using a neural network to classify climate bills and news headlines? It uses a more holisitic approach to ‘read’ the text, and in some cases (when paramaratized correctly) may outpreform traditional machine learning methods. I continue to pose the same questions in this section focusing on political polarizaiton through the lens of climate. In this notebook, I will be focusing on the partisian affiliation of both news and climate bills in addition to the sponsor state label.
McCulloch-Pitts neuron (circa 1943)
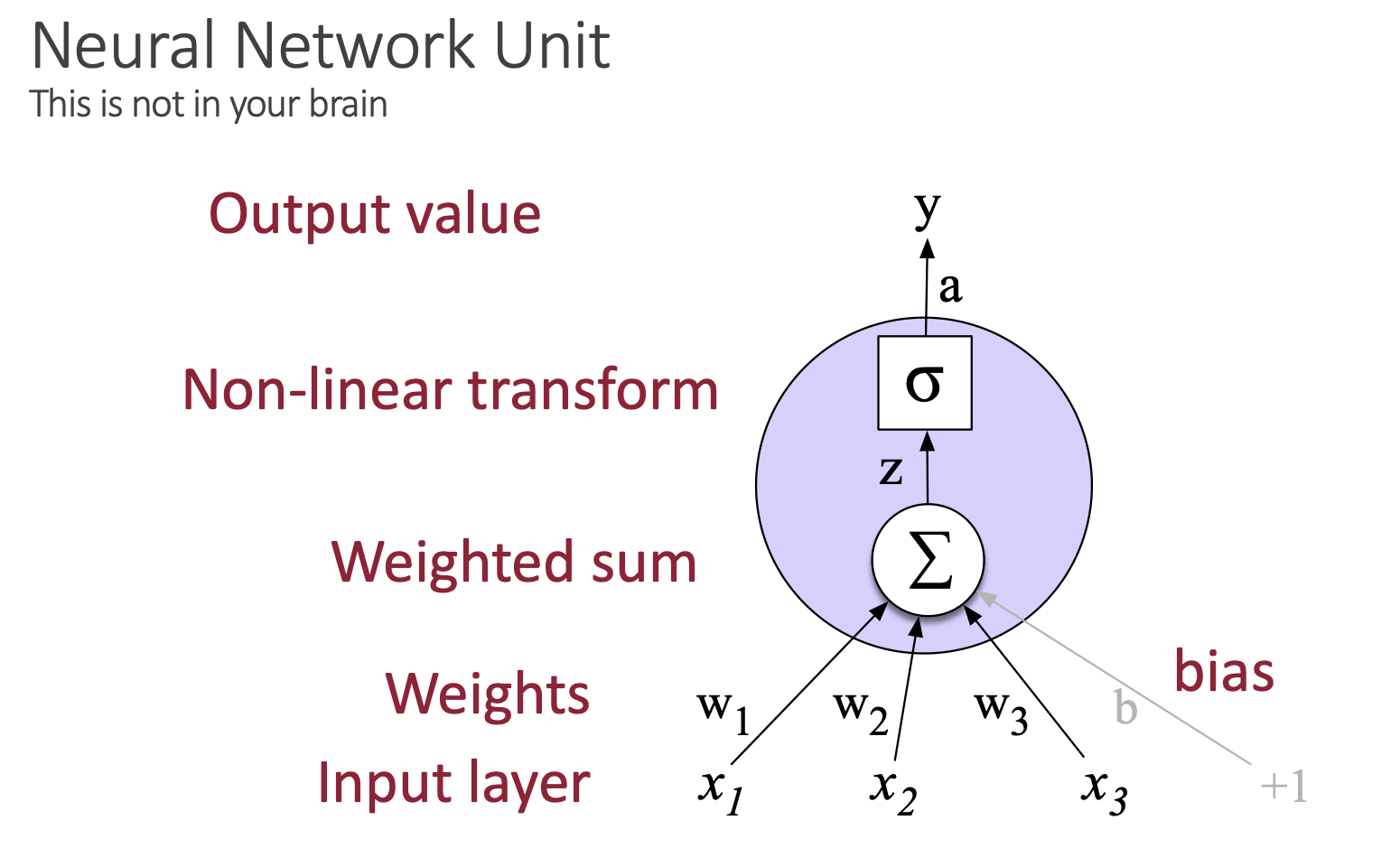
Neural Network Unit
(Neuron Citaton: BruceBlaus, Neural Network Citation and Comparison Structure: Jurafsky and Martin (2025))
Table of Contents
- Data Preparation
- Method
- Evaluating the Neural Network
- Classifying News Headline Partisian Affiliations
- Classifying Climate Bill Sponsor Partisian Affiliations
- Classifying Climate Bill Sponsor State
- Validation
- Conclusions
Data Preparation

Neural network needs text data and does not rely on counts from CountVectorizer and TF-IDF. To generate this, the original data was used that is not split and preserves the original text. This data may be found at the HuggingFace Repository for this project. While the neural network takes text data it needs to still be processed in order to have a clean training environment that is tokenized. To do so, a function was utilized to preprocess the raw text data. It is used to separate the text, lemmatize the words, and then remove any special tokens. This returns a string of the lemmatized and clean texts.
def preprocess(text : str) -> list:
## first, converting the string into a list format
text_ = text.split()
text_storage = []
## using the wordnet lemmatizer to lemmatize the words
for word in text_:
lemma = lemmatizer.lemmatize(word)
text_storage.append(lemma)
## removing all of the punctuation, special characters, digits, and trailing spaces using RegEx
text_for_cleaning = ' '.join(text_storage)
clean_text = re.sub('[!@#$%^&*()_+\'",.?*-+:;<>~`0-9]',' ',text_for_cleaning)
stripped_text = clean_text.strip()
##splitting the string back into a list
preprocessed_text = stripped_text.split()
## returning the the final processed text
return (preprocessed_text)

After processing both the bills and the news data, the sequences have to be embedded. This changes the word tokens into numerical tokens based on the order of the text. Each word in the vocabulary is assigned to a number, which is then organized into vectors which are representative of the sentence. For example the sentence “Trump’s first day in office” would then become the vector [4, 19, 32, 21, 7]. To generate a token to index vector a dictionary was used to mangage the conversions. The index zero was reserved for a ‘[PAD]’ token which is used to help truncate the input sequences. In order to preform matrix multiplication and shape the The news tokens were set to have a truncated value of 200 and an input label of 512.
 The sequences were padded and tokenized into numbers in order to be accurately passed to the Tensors. This workflow is common when training a neural network and is an accepted practice to pad the input sequences.
The sequences were padded and tokenized into numbers in order to be accurately passed to the Tensors. This workflow is common when training a neural network and is an accepted practice to pad the input sequences.
The data was split into train, test, and validation paritions. The threshold set for training was 80% with 10% reserved for testing and validation (each). The train_test_split from SciKit Learn ws utilized to generate these paritions. Using PyTorch’s Tensor Object, the vectorized data was transformed for better training. Tensor Dataset was also utilized in tandem with the DataLoader. To generate a training and testing set the code utilized the Label Encoded data (explained below) and an array of Tensor data. This reserved validation set will be held out until a model has been selected for good preformance on the train and testing sets. In addition, the labels for the news data are binary, however, this is not true for the climate bills. Each type of label for the climate bill (sponsor affiliation and sponsor state) were used to generate an individual training, testing, and validation split.
''' NEWS'''
X_train_news, X_test_and_val_news, y_label_train_news, y_label_test_and_val_news = train_test_split(truncated_sequences_int_news, labels_full_news_party, test_size=0.2, random_state=123)
X_test_news, X_val_news, y_test_label_news, y_val_label_news = train_test_split(X_test_and_val_news, y_label_test_and_val_news, test_size=0.5, random_state=42)
Keeping the training, testing, and validation sets completely separate are important. If this is not maintained, the model may be overfit, incorrect results are reported, or the application of the model on truly held out data will be incorrect. In addition, the training data, testing data, and later the validation data must originate from similar instances or the model will not preform as expected. For example, if a model is trained on niche academic representations of partisian affiliations, if the model was tested on Reddit slang and discourse about partisian affiliations, because the language used is fundamentally different - and with a different goal, it will not preform accurately.
Labels
The Label Encoder from SciKit Learn was utilized to encode the labels. This function also allows for reverse encoding, so the development of visualizations are rooted in text labels - not numerical labels. This is particularly important non-binary labels, such as the Sponsor State, which may have multiple categories.
''' NEWS LABELS '''
labels_full_news_party = news_data_raw['Party'].to_list()
label_encoder = LabelEncoder()
labels_full_news_party = label_encoder.fit_transform(labels_full_news_party)
As noted above, the Climate Bills have two labels of interest - partisian affiliation and sponsor state, and for these reasons, the labels were generated separately - one for each. These are kept separate and stored with their respective training, testing, or validation split, in order to assess the models preformance.
Method
The Neural Network was hand coded. As introduced earlier, the network requires a few different layers. The data preparation discussed above prepared the original input layer or the embedding layer. The padding_idx token was noted earlier as 0, and the number of embeddings are the total vocabulary.
''' EMBEDDING LAYER: '''
self.embedding = nn.Embedding(num_embeddings=num_embeddings, embedding_dim=embedding_dim, padding_idx=padding_idx)
The subsequnet layers are the first linear layer, then an activation, the second linear layer, and finally the sigmoid:
''' MODEL ARCHITECTURE '''
self.linear1 = nn.Linear(input_size, hidden_size)
self.activation = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
These layes are instantiated as functions, howver during the forward pass, where the model is ‘learning’ the current x or the token is passed into the calculations.
''' FORWARD PASS '''
def forward(self, x):
x = self.embedding(x)
x = torch.mean(x, dim=1)
x = self.linear1(x)
x = self.activation(x)
x = self.linear2(x)
x = self.sigmoid(x)
return (x)
An early stop function was also implemented in the case that the model was overfit on the data and during the validation of the model the loss was actually increasing. Finally, a training loop was developed in order to assess the validity of the model and compare between paramaterized models. To address the above note of non-binary labels for the Climate Bills, the training loop is able to alter the instantiation of the model in order to take multiple options for the labels.
The model had a
Evaluating the Neural Network
To evaluate the model, it is asked to predict (with no altered gradient - or it would result to training on the test set!) the testing and validation sets. The predictions are then stored and the evaluation metrics are computer. The evaluation metrics are discussed at length in the Naive Bayes section of the project page. In addition, a similar confusion matrix was genereated using the same code (also in Naive Bayes) to illustrate differences between the models.
def evaluation(model, test_loader):
for batch in test_loader:
test_inputs, test_targets = batch
with torch.no_grad():
test_outputs = model(test_inputs)
predictions = test_outputs.view(-1)
predictions = torch.tensor([1 if x >= 0.5 else 0 for x in predictions])
accuracy = accuracy_score(test_targets, predictions)
precision = precision_score(test_targets, predictions)
recall = recall_score(test_targets, predictions)
f1 = f1_score(test_targets, predictions)
print(f'accuracy: {accuracy}')
print(f'precision: {precision}')
print(f'recall: {recall}')
print(f'f1: {f1}')
return (predictions, test_targets, accuracy, precision, recall, f1 )
Classifying News Headline Partisian Affiliations:
The parameters and evaluation metrics are reported in the table below. For each different iteration of the parameters, they were recorded in order to select the most effective model for subsequent discussion. In addition, a lineplot was generated to identify the training versus validation loss per epoch. This type of metric provides insight into what model is the most effective.
| Test Number | D | H | Batch Size | Epochs | Epochs Completed | Learning Rate | F1 | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 50 | 50 | 8 | 500 | 3 | 0.2 | 0.64 | 0.47 | 0.47 | 1 |
| 2 | 50 | 50 | 4 | 100 | 23 | 0.005 | 0.49 | 0.59 | 0.61 | 0.41 |
| 3 | 500 | 500 | 4 | 100 | 100 | 0.005 | 0.50 | 0.57 | 0.56 | 0.46 |
| 4 | 500 | 500 | 4 | 100 | 18 | 0.0005 | 0.53 | 0.59 | 0.59 | 0.48 |
| 5 | 500 | 500 | 8 | 100 | 100 | 0.0005 | 0.45 | 0.56 | 0.55 | 0.38 |
| 6 | 700 | 700 | 4 | 100 | 60 | 0.0001 | 0.48 | 0.58 | 0.59 | 0.41 |
| 7 | 500 | 500 | 8 | 500 | 255 | 0.0001 | 0.57 | 0.67 | 0.75 | 0.46 |
| 8 | 500 | 500 | 4 | 500 | 500 | 0.0001 | 0.47 | 0.62 | 0.70 | 0.35 |
| 9 | 500 | 500 | 4 | 1000 | 586 | 0.0001 | 0.50 | 0.62 | 0.66 | 0.41 |
| 10 | 500 | 500 | 16 | 1000 | 1000 | 0.0001 | 0.52 | 0.59 | 0.60 | 0.46 |
The model which preforemd the best was determined using F1, as it is a holisitc understanding of multiple different measures, this will also be determined using a look at the other evaluation metrics as well. Model 7 had the highest F1 score and the highest supporting evaluation scores.
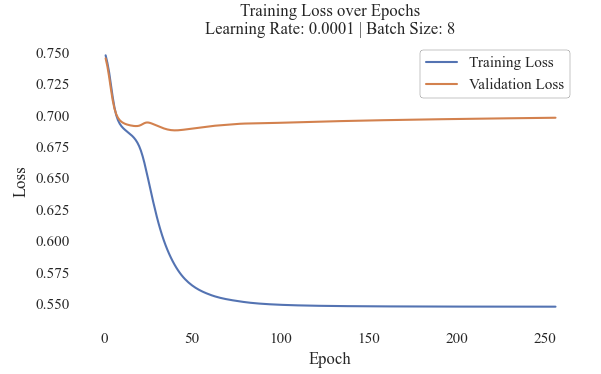
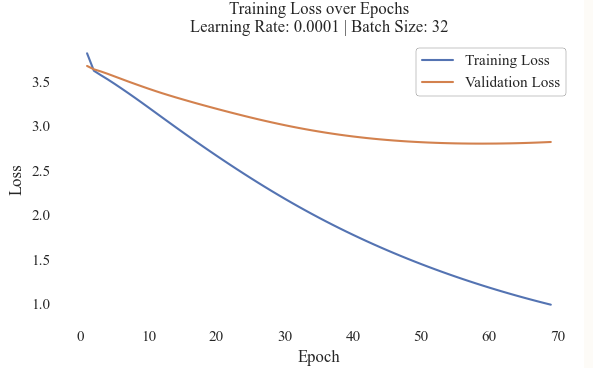
Test 7 Model Loss
Test 7 Model Loss
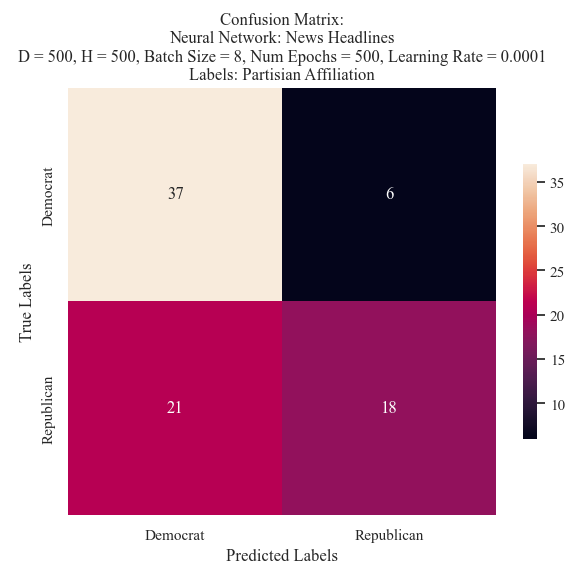
The few epochs completed by the model indicates that the early stop was utilized in order to prevent overfitting. However, such an early stop shows that the model is deeply struggling to learn on the text that it is provided with. After 250 epochs, the training loss was 0.55 and the validation loss was around 0.70. This was then validated using a visual confusion matrix. The model was more accurately able to predict the Democrat Labels, however, it had a strong tendancy to only predict Democrat Labels. The balance of the testing corpora was 43 Democrat labels and 39 Republican labels. This implies that the Neural Network was able to accurately classify news headlines and labels 57% of the time, with higher accuracy for Democrat mentions.
Implications of this accuracy suggests that there is some differences in language used to define partisian affiliations through news headlines, however, these distinctions are not always clear. This is a finding that was evidenced through Naive Bayes and Support Vector Machines as well. Naive Bayes had observed a similar misclassification pattern, predicting Democrat when the label was actually Republican. This is interesting because it is consisteny across models, and suggests that instead of one model preforming poorly there is a trend throughout different training and pre-procoessing techniques. The Neural Network achieved a higher accuracy rate of 67% (compared to 57%), higher precision 75% (NB: 57%), but lower recall of 46% (NB: 57%). In comparison to the SVM the Neural Network was able to preform better on all metrics except for recall. Further explorations of accuracy will be discussed using the helf out testing set (different than the validation and training) in the next section.
Classifying Climate Bill Sponsor Partisian Affiliations:
A similar iteration process to identify a potential best model was utilized for the climate bill sponsor partisian affiliation as well. It should be noted that for this data the labels are not binary as the climate bill sponsor may be independent as well. In addition, due to the truncation of the otherwise lengthy data, this may result in a more challenging prediction task. This is not so clearly evidenced in the evaluation table presented below. As demonstrated through the epochs completed, this data had a problem with overfitting - despite rather small learning rates. This caused the early stopper function to trigger, thus the training was cut short as soon as the function detected overfitting. It should be reiterated that the train test split for each model used the same data and the same random seed. This means that the data used to test the models were consistent across iterations.
While the models were able to achieve relatively high F1 scores (in addition to high evaluation scores all around), however the issue is that the models struggled to learn features of Independent affiliated sponsored bills. This presents a challenge, as other models such as Naive Bayes, were able to identify this distinction. Only one model (2) was able to identify the Independent label, but it did not predict correctly.
| Test Number | D | H | Batch Size | Epochs | Epochs Completed | Learning Rate | F1 | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 50 | 50 | 16 | 5 | 4 | 0.2 | 0.37 | 0.59 | 0.29 | 0.5 |
| 2 | 500 | 500 | 16 | 500 | 4 | 0.002 | 0.53 | 0.81 | 0.54 | 0.53 |
| 3 | 500 | 500 | 8 | 500 | 4 | 0.002 | 0.81 | 0.82 | 0.81 | 0.80 |
| 4 | 500 | 500 | 16 | 500 | 6 | 0.0009 | 0.82 | 0.83 | 0.82 | 0.82 |
| 5 | 250 | 250 | 16 | 500 | 5 | 0.002 | 0.82 | 0.83 | 0.82 | 0.82 |
| 6 | 500 | 500 | 32 | 500 | 29 | 0.0001 | 0.54 | 0.81 | 0.54 | 0.53 |
| 7 | 250 | 250 | 16 | 500 | 6 | 0.001 | 0.80 | 0.81 | 0.80 | 0.80 |
| 8 | 300 | 300 | 16 | 500 | 4 | 0.002 | 0.81 | 0.82 | 0.82 | 0.80 |
| 9 | 500 | 500 | 16 | 500 | 24 | 0.0001 | 0.79 | 0.80 | 0.79 | 0.79 |
| 10 | 499 | 499 | 31 | 1000 | 21 | 0.00015 | 0.81 | 0.82 | 0.81 | 0.81 |
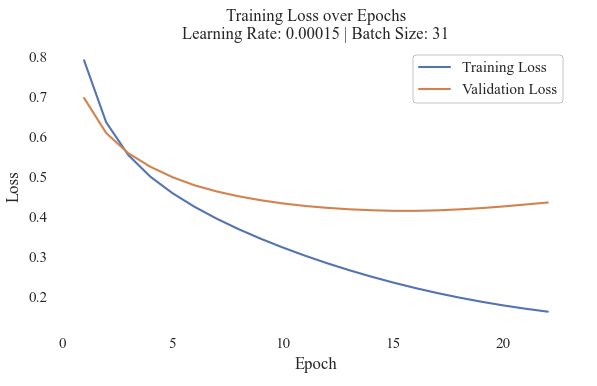
Test 10 Model Loss
This model was able to completed 20 epochs, but experienced overfitting around Epoch 15. The training loss decreased, with a clear elbow at about the fourth epoch, which was also when the validation departed from the continual decrease with the training losses.
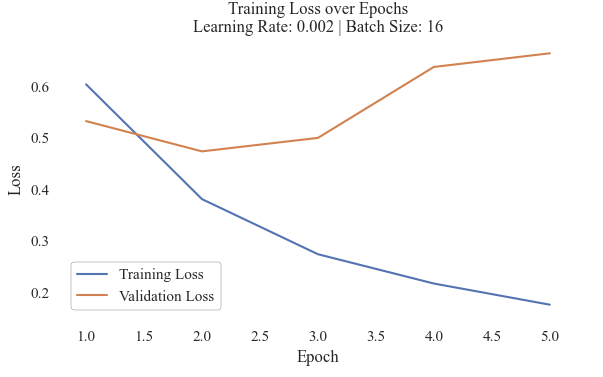
Test 2 Model Loss
This model only completed five epochs. At epoch three, the model began to overfit as the validation loss began to increase and continue to do so.
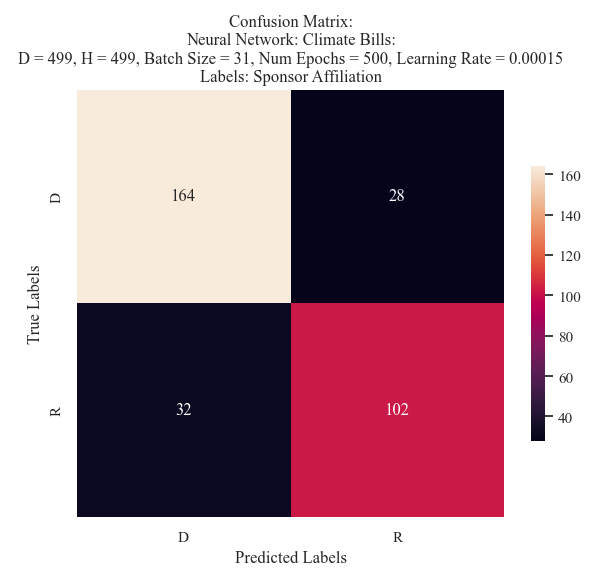
Test 10 Confusion Matrix
This model predicted a relatively accurate split between the Democrat and Republican affiliated bills - however, it was not able to learn the features of an Independent bill sponsor. Similar to other models, the model was more likely to predict Democrat than Republican.
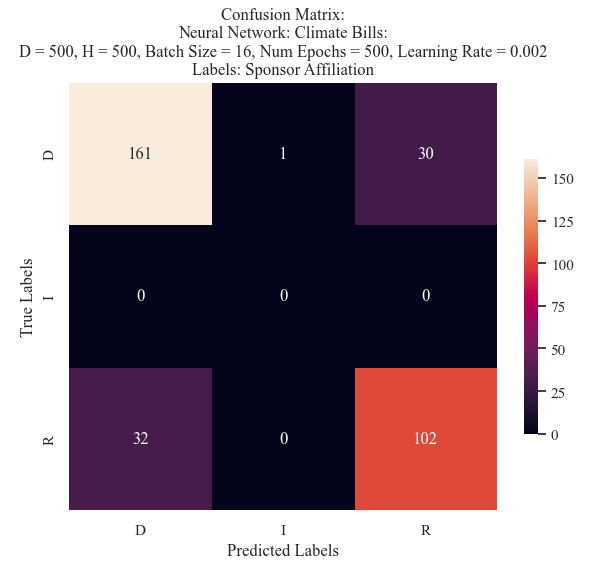
Test 2 Confusion Matrix
This model preformed nearly identical to that of Model 10, however, it was able to learn about the Independent party. While it did misclassfy it during its prediction, it still understood that it was a viable label.
These results make it challenging to compare and select a best model. Model 10 recieved a much higher F1 score (nearly 30% improved) and an increase in both precision and recall. However, it is clear that the model did not learn all of the features of the data. Yet, due to its evaluation metrics overall the 10th model was selected to be utilized in further comparisons.
Classifying Climate Bill Sponsor State:
There was a total of 54 different options for state Sponsor. This is a challenging prediction task, and does not afford the model much room for error. In the evaluation presented here, the patterns of learning will be identified - not so much the models true ability to learn, as it underpreformed on all metrics utilized in this test.
| Test Number | D | H | Batch Size | Epochs | Epochs Completed | Learning Rate | F1 | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 50 | 50 | 16 | 5 | 4 | 0.2 | 0.004 | 0.113 | 0.002 | 0.020 |
| 2 | 500 | 500 | 32 | 500 | 68 | 0.0001 | 0.015 | 0.043 | 0.019 | 0.016 |
| 3 | 750 | 750 | 16 | 500 | 4 | 0.005 | 0.016 | 0.055 | 0.018 | 0.018 |
| 4 | 50 | 50 | 200 | 500 | 7 | 0.005 | 0.016 | 0.040 | 0.021 | 0.015 |
| 5 | 50 | 50 | 200 | 500 | 402 | 0.0005 | 0.025 | 0.071 | 0.024 | 0.029 |
| 6 | 100 | 100 | 250 | 500 | 331 | 0.00005 | 0.018 | 0.052 | 0.019 | 0.020 |
| 7 | 250 | 250 | 250 | 1500 | 99 | 0.00005 | 0.023 | 0.064 | 0.027 | 0.023 |
| 8 | 500 | 500 | 16 | 1500 | 651 | 0.00001 | 0.02 | 0.06 | 0.02 | 0.02 |
| 9 | 500 | 500 | 16 | 1500 | 10 | 0.001 | 0.01 | 0.05 | 0.01 | 0.01 |
| 10 | 700 | 700 | 8 | 1500 | 5 | 0.01 | 0.01 | 0.04 | 0.01 | 0.01 |
This model was unable to learn any of the features and did not achieve any evaluation metrics (except one) over 1%. This implied that using a neural network for this kind of data, and in its truncated form, may not be the most appropriate. Future research may consider training a neural network with the entirety of the corpus, not just the first 200 characters. Although the model did not train appropriately, its predictions match that of some of the other models utilize to classify the Bill Sponsor State.
Log Loss During Training
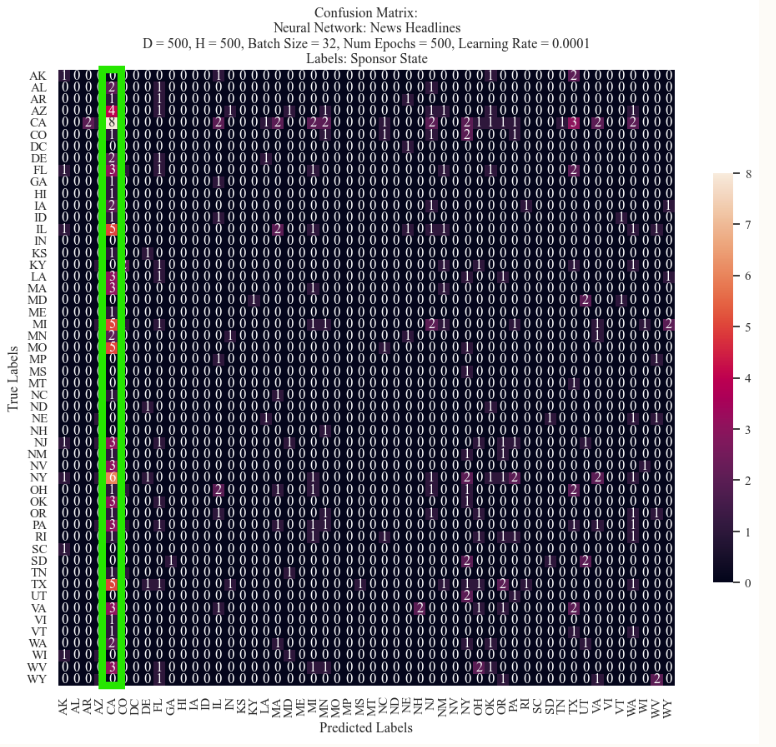
Classifier Results: Sponsor State
The Log Loss shows that the model began with a much higher log loss than the News Predictions or the Proposed Cliamte Predictions. This supports what was demonstrated in the later accuracy scores is that the models predictions are much further away from the true label - due to the sheer number of labels available for the model. It is much more likely for while the model is intially taking steps with the learning rate to identify where it needs to be, due to the success of random guessing. This is not an affordance of attempting sponsor state classification.
Through Naive Bayes it became clear that California had the most classifications, however the model did not struggle to predict as much as the neural networks. While the neural network was able to identify this frequency, it assumed nearly everything to be the label ‘California’ (highlighted in green on the image). This suggests that California’s prevalence may introduce difficulties in classification for models which are not as robust. In addition, this large column suggests that the model did learn the label, just not very well. In comparison to Support Vector Machines, this is some improvement.
Validation
Validation is a process used that is similar to testing and can help provide insights into how the model is preforming. The validation set was split from the remainder of the training set and composes 10% of the dataset. Only the partisian affiliations are represented here as it was discussed earlier about the shortcomings of training the neural networks on a large corpora of labels.
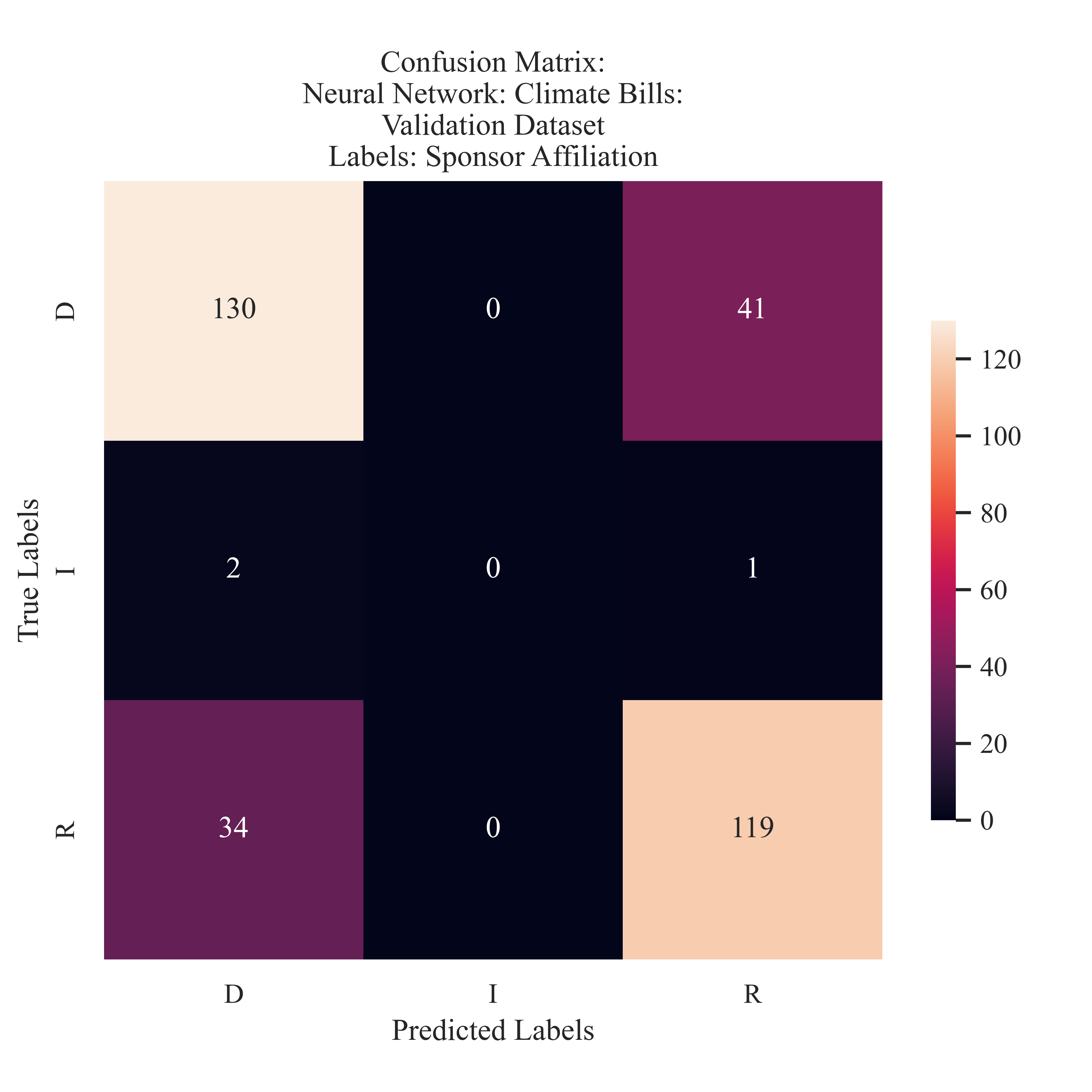
Climate Bills Sponsor Affiliation
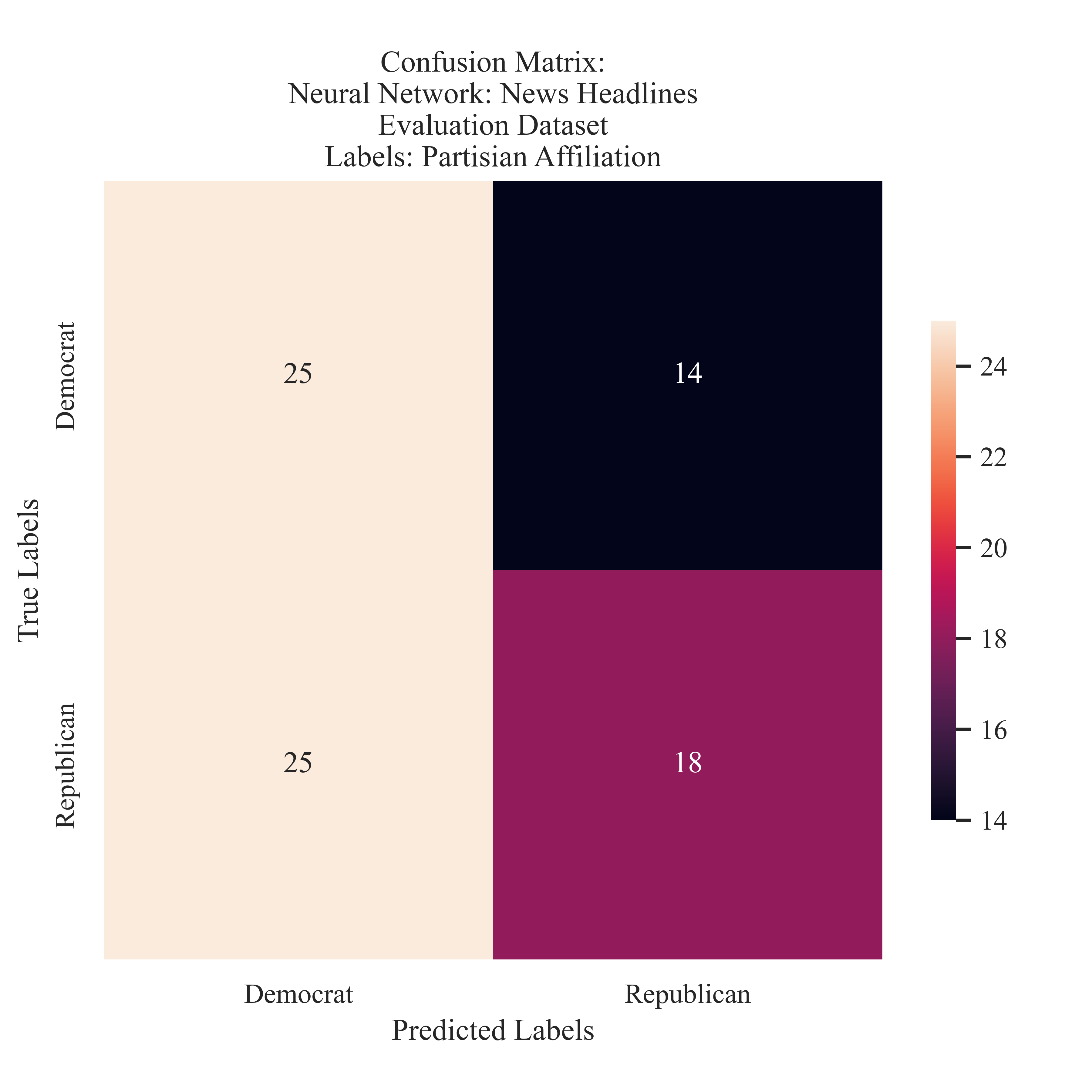
News Headline Partisian Affiliation
Climate Bills: Sponsor Affiliation During the validation of this model, it was able to successfully (somewhat) identify all three labels which were present, while unable to predict correctly the Independent affiliation, additional data may have been able to bolster its accuracy. In this, the majority of the validaiton set was accurately predicted. The model had a tendancy to misclassify more true Democrat sponsored bills as Republican. This is a different pattern than in the Naive Bayes or SVM, as those models both predicted the inverse. This model had an 81% F1 score. This means that the majority of the labels are able to be predicted correctly, but there still are some errors. Expanding into a more robust and lengthy dataset may be able to increase the validity of this score.
News Headlines: Partisian Affiliation The validation of the news model provided slightly less balanced resutls, however this does not suggest overfitting due to the relatively small size of the validation corpus. The model was more likely to predict Democrat for Republican labeled articles, that the number of true Republican predictions. This suggests that through the lens of the neural network, it was not as clear the differences when discussing partisian matters, and identified a large proporition of both Democrat and Republican articles to be affiliated with the other. It must be reiterated that the model had only a 57% F1 score, thus, it is up for further discussion if this finding is valid or an error on the models behalf.
Conclusions
The neural network provided further insight into how labeled data may be used to parition and classify data. The results here were promising, and with additional computational resources to train full models without truncating the data, the models may experience increased accuracy. The ability for a neural network to classify partisian affiliation suggests that through its deep learning it may be able to interpret what language is used form different ideologies within United States politics. Applying unsupervised learning methods to a discussion about nuanced partisian ideology indicates some capacity for the models to detect such nuances. Larger training data may support a higher accuracy and eventually increase the accuracy to a confident position in an attempt to ‘predict’ the future. By applying classifiers to language around bills, when not everything is yet known may provide insight into partisian collaborations or divide through these methods.